
Overview
At Sythe Labs, we secure not only your application, but the constituent components that make up that application. In today's blog post, we'll be taking about how Software 3.0 is slowly taking over, and what this means for the changing landscape of security.
What Is Software 3.0?
Software 3.0 is a term which canonically refers to the modern advent of LLMs in the wider software landscape. Since their emergence, they've fundamentally changed how software is written, interacted with, and run. The eventuality of this outcome is software which is "malleable", meaning that the prompt itself is the software, and the underlying implementation takes on another dimension. Software 1.0 is rigid and exact, whereas Software 3.0 is fluid and purpose-built. This is not the current state, but it's easy to see how we might end up there at some point.
What's The Difference Between Them?
The differences are pretty simple. Taking from Andrej's video linked above, Software 1.0 is the physical code that runs and executes instructions. For example, this would be most of the software you interact with at the time of writing. When you open your smartphone, you're utilizing Software 1.0. It's literally the code that runs, and you can guarantee (barring cosmic rays) that this software is guaranteed to run the exact same way.
Software 2.0 shifts the boundaries a little bit. Instead of having rigidly defined problems and solutions, which the field of algorithms is very well-suited for, Software 2.0 begins to move toward a more open-ended interpretation of the end goal. For example, consider a recommendation system. There does not yet exist an algorithm that can generalize to all the users that you might have on your platform which can also be written purely in a Software 1.0 lens. This is because a recommendation, just like if you were giving a recommendation to a friend, transcends beyond rigid constraints that are common in Software 1.0. If I were to recommend a movie, some example features that I might take into account are their specific tastes, the time of year, current events, their mood, etc. Translating this into a computer program might be theoretically possible, but it would be impossibly complex. As a result, some type of statistical or numerical method is utilized to optimize for the best recommendation. Think of these almost like an FPGA: insanely good at the narrow task, but terrible at everything else.
In Software 3.0, the software becomes the platform. The LLM as an execution engine is now a fully stochastic (though, within many use-cases, reasonably predictable). I can define a loose set of constraints and, depending on the model (ex. claude code), I can obtain a result which is exactly, or close to, what I was looking for.
How Does Security Change for Software 3.0?
Consider a mobile app, which would canonically be considered Software 1.0, and might also include some Software 2.0 features. An engineer can easily define security guardrails in the application to ensure it’s used properly. They could distribute the application via secure channels like an App Store that “double check” proper controls. They can then add authentication and use strong security when storing user passwords (you are hashing your passwords, right?). They can then also add guardrails to certain features that they might charge for, or only make such features available to certain types of users (ex. Enterprise). In the space of Machine Learning (ML) engineering, we define an adversarial attack as one which can trigger the model to output something undesired. In a typical application security context, this is akin to something like a misconfiguration in an AWS s3 bucket (we’ve all been there) leading to leakage of its contents. This is fixed with a simple configuration change, and any good auditor would catch these issues immediately.
LLMs and the broader AI ecosystem present challenges that make such remediation much more difficult. Most of contemporary AI, while insanely advanced, is still in its infancy in terms of trust, reliability, and consistency. By extension, LLMs further increase this potential attack surface due to their handling of multiple modalities of input (called “multi-modal”). We still don’t fully understand what models do when they make a decision, and we rely on a whole slew of different evaluation criteria just to make sure they’re working as we expect. Testing correct outputs against a control using evaluation criteria such as the cosine similarity score are not currently in widespread use. This is due to a number of reasons, but some of them are the lack of standardization (though this is being worked on), the imprecision of evaluating LLM output (how do we measure Software 3.0 with Software 1.0?), and defining the control to test against are all examples of where a naive measurement such as this may fall apart under scrutiny.
Furthermore, we see lots of state of the art approaches rushing through the floodgates, most notable at the time of writing is the deepseek-r1 model, trained in a fraction of the time, and at a fraction of the cost of the comparatively exorbitantly expensive OpenAI o1 model. These models all exhibit different characteristics, have different training processes, and are designed with different use-cases in mind. While there are standard benchmarks like SWE-bench (though some argue it's becoming susceptible to Goohart's Law), there's no easy way to evaluate a system like you would have with Software 1.0 or 2.0. This is all to say: AI is hard, and LLMs are even harder.
Why AI Security Is Hard
Tradsec In The Context of Software 2.0
Let’s consider everyone’s favorite groundbreaking AI model, YOLO. At the time, YOLO was a monumental improvement over existing methods. It provided a novel architecture which, compared to the complexity of today’s systems, is relatively simple to implement (even from scratch!), and was quite fast for real-time computer vision tasks. One key quirk of neural networks more broadly, however, is that anyone with access to the training set can change the input imperceptibly and lead to vastly unexpected outputs. So a disgruntled data scientist or malicious engineer could theoretically destroy your training set, leading to huge model performance degradation and potentially harm to your users depending on the use case.
Do you have an action plan for dealing with rogue employees? Sythe Labs offers a comprehensive adversarial evaluation of your target infrastructure to make sure that no one, not even insiders, are capable of harming your critical products. Get in touch today!
AI attacks are not limited to just insiders, however. End-users can manipulate inputs to get your model to behave in ways that you didn’t expect. In a short article, David Silar provides some great examples from the Stanford CS231n class on convolutional neural networks:
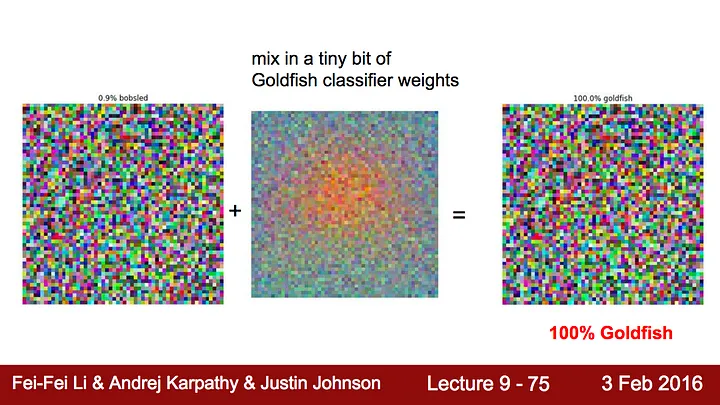
Now, compare this to another example

You can see the full set of slides here. We see that this convolutional neural network can be tricked relatively easily by just providing some of the latent information from another training setup.
In the real world, hackers have demonstrated that these same techniques can be used to fool self-driving cars by obscuring stop signs, forcing cars to run through intersections. This has resulted in at least one fatality.
These outcomes can be really challenging to plan for. Companies like Google or Meta mitigate such negative externalities by having enormous sets of training data, specialized models, pre-processing steps for input data, and generally extremely sophisticated processes in place for handling such emergent scenarios. They also have dedicated security staff whose whole mission is to prevent these types of attacks from happening. Even if such attacks are impossible to prevent 100% of the time, making the barrier as high as possible is a great way to make sure that almost no one can exploit your system. At Sythe Labs, we provide this service and can work with your team on an evaluation plan to assess the security of your deployed AI models, making sure that you’re as secure as possible from threats. In the next section, we’ll explain why LLMs are an even bigger hurdle to overcome.
Tradsec In The Context of Software 3.0

There's a lot of gatekeeping in AI, and while I don't necessarily fully agree with the above characterization of LLM datasets, the point remains the same: LLMs have access to one of the largest datasets ever conceived by mankind, and are being asked to do things no AI system has ever been used for in the past. This, coupled with the fact that many people that deploy these systems are familiar at just a cursory level with the mechanics, and you have a system that is ripe for exploitation.
Why LLM security is hard(er)
The threat model of LLMs is vast due to the size and scope of their training data. Where prior models for things tasks such as vision or NLP have typically (but not always) used specific, anonymized training data that was carefully pruned to maintain privacy etc, LLMs in the modern age have had nearly the entire internet hooked into them. Without open access to evaluate these datasets, it’s hard to say how much of this data was anonymized or verified formally by third parties. Because of this, LLM systems know about a lot of things and, as a result, the contemporary understanding is that these systems can excel in a broad range of tasks. As hackers, our first inclination is to dig into the details and uncover where the fringes of these systems are.
Non-Deterministic Systems Beget Compromise
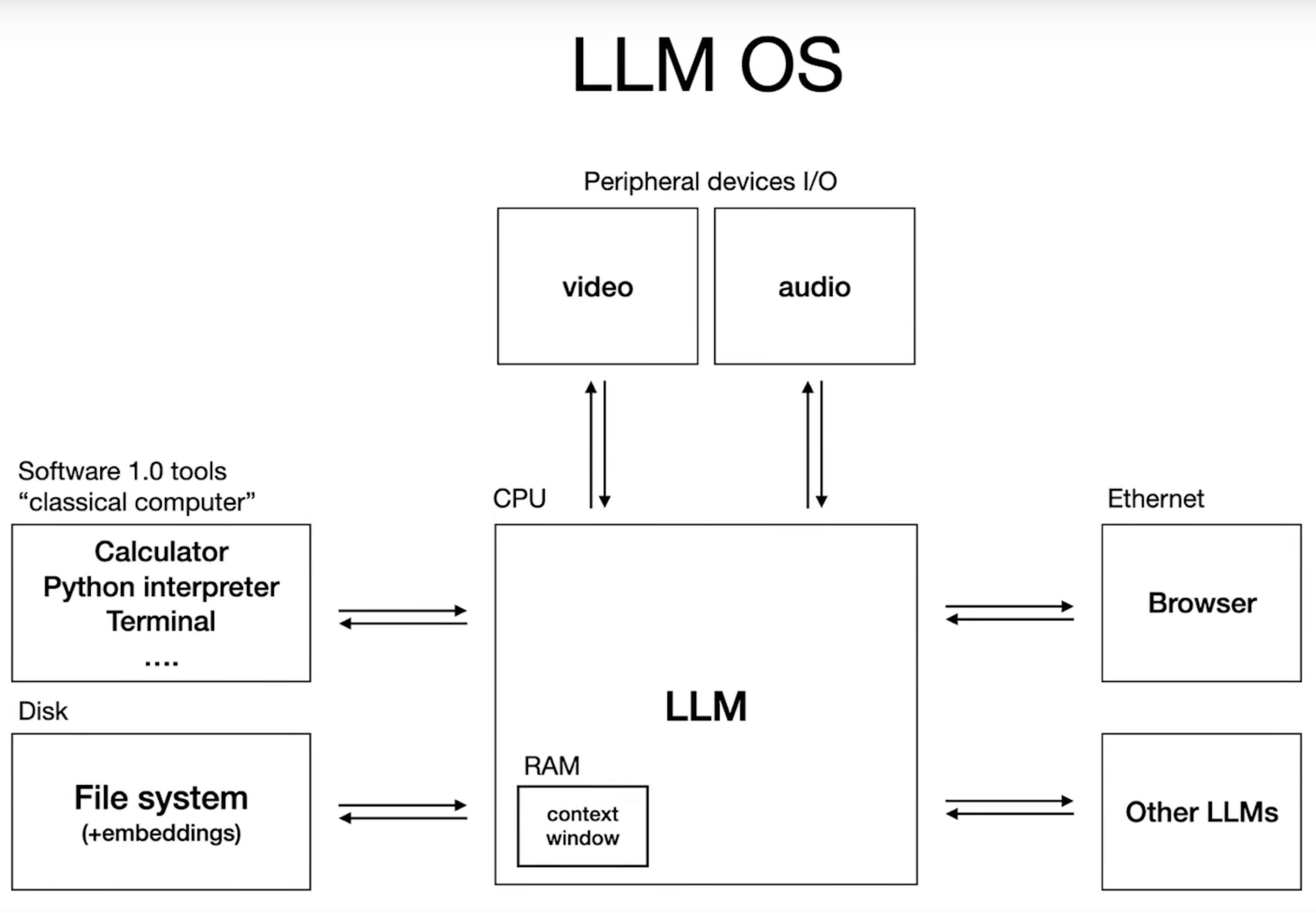
Let's steal a slide from Andrej's talk to motivate our discussion.
LLMs, like many machine learning systems, model probability distributions. In the case of LLMs (and other ML systems which exhibit generative characteristics) they model the probability of the next output given previous outputs. In this sense, they can be thought of as very complex conditional probability estimators. The conditional probability, as described by my alma-mater (boola-boola!) can be described as the following:
The conditional probability of an event B is the probability that the event will occur given the knowledge that an event A has already occurred. This probability is written P(B|A), notation for the probability of B given A. In the case where events A and B are independent (where event A has no effect on the probability of event B), the conditional probability of event B given event A is simply the probability of event B, that is P(B).
Approximation is everywhere, from numerical optimization to game theory. Game theory even stipulates that most of human actions are utilizing a mixed strategy (i.e. sampling from a range of actions along a probability distribution). However, this is not necessarily what we want in computational environments. Computers are great because they're exact. This property is called "determinism". A deterministic system is one which, given any manner of input, will always produce an expected and repeatable output. If I add 2 and 2, I will always get 4.
Author's note: This language is intentionally a bit imprecise. Nothing is truly deterministic, and in environments such as distributed networking or concurrent programming, there are theoretical infinite lapses in time where a system can idle waiting for an event to occur. I'm speaking broadly here about the outcomes, however. Even if infinity (though it's pretty asymptotic) is the end state, it still could eventually happen.
The introduction of non-determinism into general purpose computing environments has the potential to introduce second-order effects as a result of the inability to predict with certainty what the output of a given model will be. This has had real-world effects too. From Apple Delaying Apple Intelligence and--getting sued for it--to GM accidentally selling someone a car for a dollar, engineers must be very careful about how they roll out these systems, and how to keep them secure.
Now consider the operating system model as described by Andrej. Where traditional modes of computation such as Turing machines, Bell Labs' work, and beyond had rigid and verifiable components which made up the unit, LLMs shift the paradigm entirely, and create a whole new mode of operation for the computation that the user is looking to perform.
Now, none of this is to imply that LLMs don't have use, and that your product is doomed to sell your product at a catastrophic loss. Instead, we want to highlight just how novel the entire computing landscape has become, and how the problems being solved today are nowhere near as cut and dry as they used to be. Andrej describes the current year of writing as the 1960's of computing, an opinion I fully agree with. Reading and writing to an LLM is just not efficient, not scalable and, frankly, not even that easy yet (see our prior entry on LLM prompting). There needs to be a fundamental shift in how the public understands computing--particularly in terms of what it means for a computer to produce an expected output from a given set of instructions. This shift also needs to be made in the security landscape as well.
What's the solution?
The solution is the same as it has always been: don't skimp on security. OpenAI has done great work getting around issues like DAN Prompts using RLHF, and other fine-tuning methods to teach the model to ignore these types of prompts, but it's not enough to simply fine tune your production model. You need a robust pipeline that is capable of doing pre and post-processing on the inputs and outputs such that you know for sure that certain sensitive subjects are ignored at all times. It's no longer enough to simply hook the OpenAI API up to your webpage, feed it some data, and start selling your new SaaS. You need to take an intentioned approach to ensuring that your system is secure.
Security Tactics
One of the easiest tactics is to hire the experts. I know I know, shocker I’d suggest this on a company blog but seriously! Sythe Labs and other excellent firms employ staff whose entire job it is to break your system so that way you can guarantee that the bad guys don’t get in there first.
Secondarily, you’ll want to leverage gasp classical NLP techniques! A good old fashioned BERT model can give you extremely accurate sentiment analysis on inputs from untrusted sources for pennies. This can be used as a gateway into your LLM pipeline to ensure that the user is asking the right questions. You can use these techniques for analyzing intent, context, and perform routing so that way your LLM (or, in a multi LLM setup, your specialist) can always provide maximum value. This minimizes costs along a number of dimensions. Not only are you wasting less tokens on bogus outputs from people trying to trick your model into saying slurs or ingesting broken data, but you also get the ability to have a (while still non-deterministic) much more durable process in place for keeping bad guys out. Sythe Labs can even advise you on how to secure this system, what keywords and categories make the most sense to use, and how to keep your optimized ML routines secure from abuse.
Conclusion
Overall, ML is hard, LLMs are harder, and how you prepare for the worst of times, will make sure that you’re ready to take swift advantage of the best times. Sythe Labs is a dedicated security partner, and we’re with you every step of the way to help secure your infrastructure from the bad guys waiting to make your company a victim. Interested in learning more? Please reach out today!